https://medium.com/dsckiit/an-image-classification-model-with-5-lines-of-code-4d76e8fbf367 bt7.bcrs@gmail.com Bantuda7
I’ll
demonstrate step-by-step how you can build your own image classification model
using a custom dataset and just 5 lines of logic. To make things interesting,
my model is going to classify minions. The layout of this tutorial is going to
be -
1.
Create a dataset.
2.
Upload it to our notebook.
3.
Train our model.
4.
Interpret the results.
Before
that let’s take a few steps back and know what we’re working with here. Image
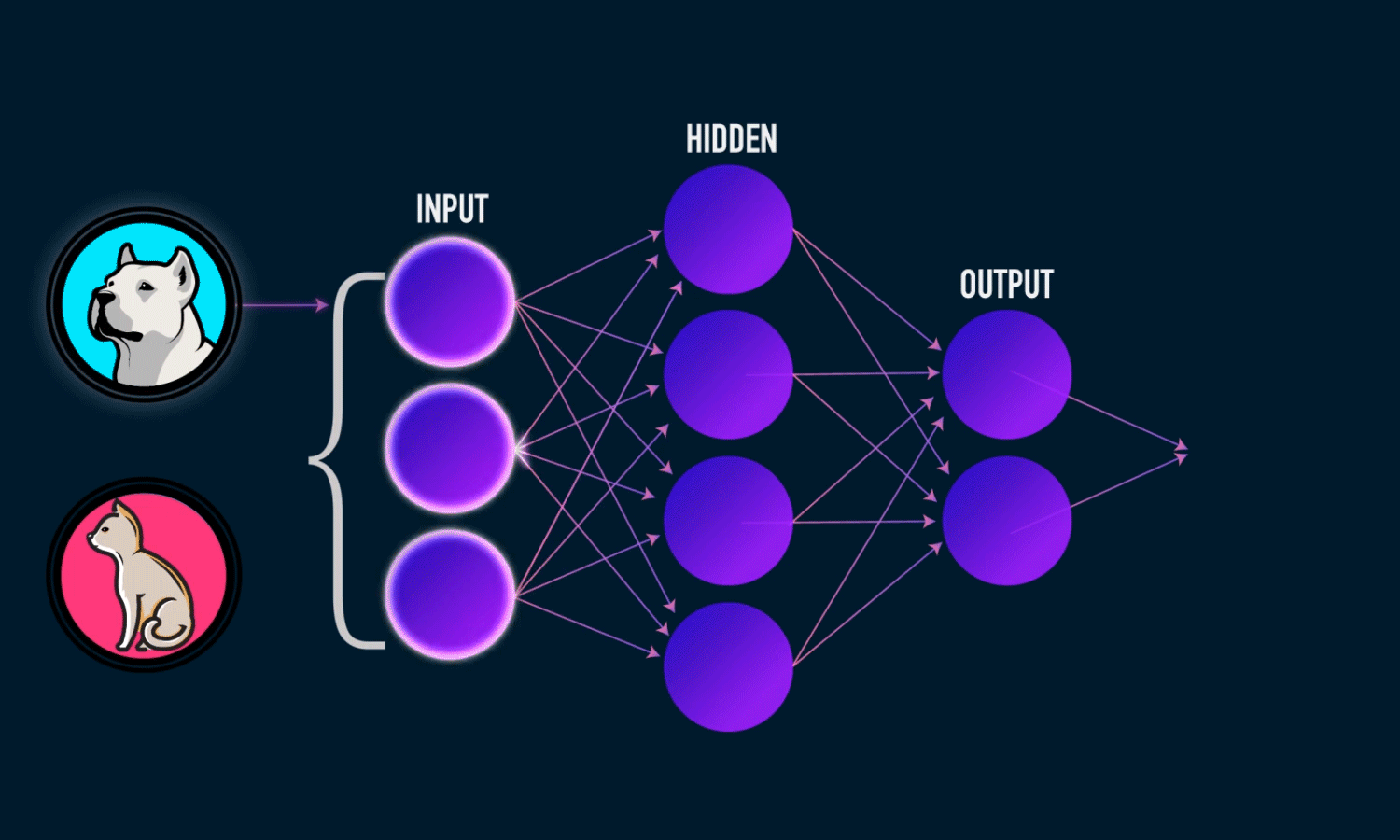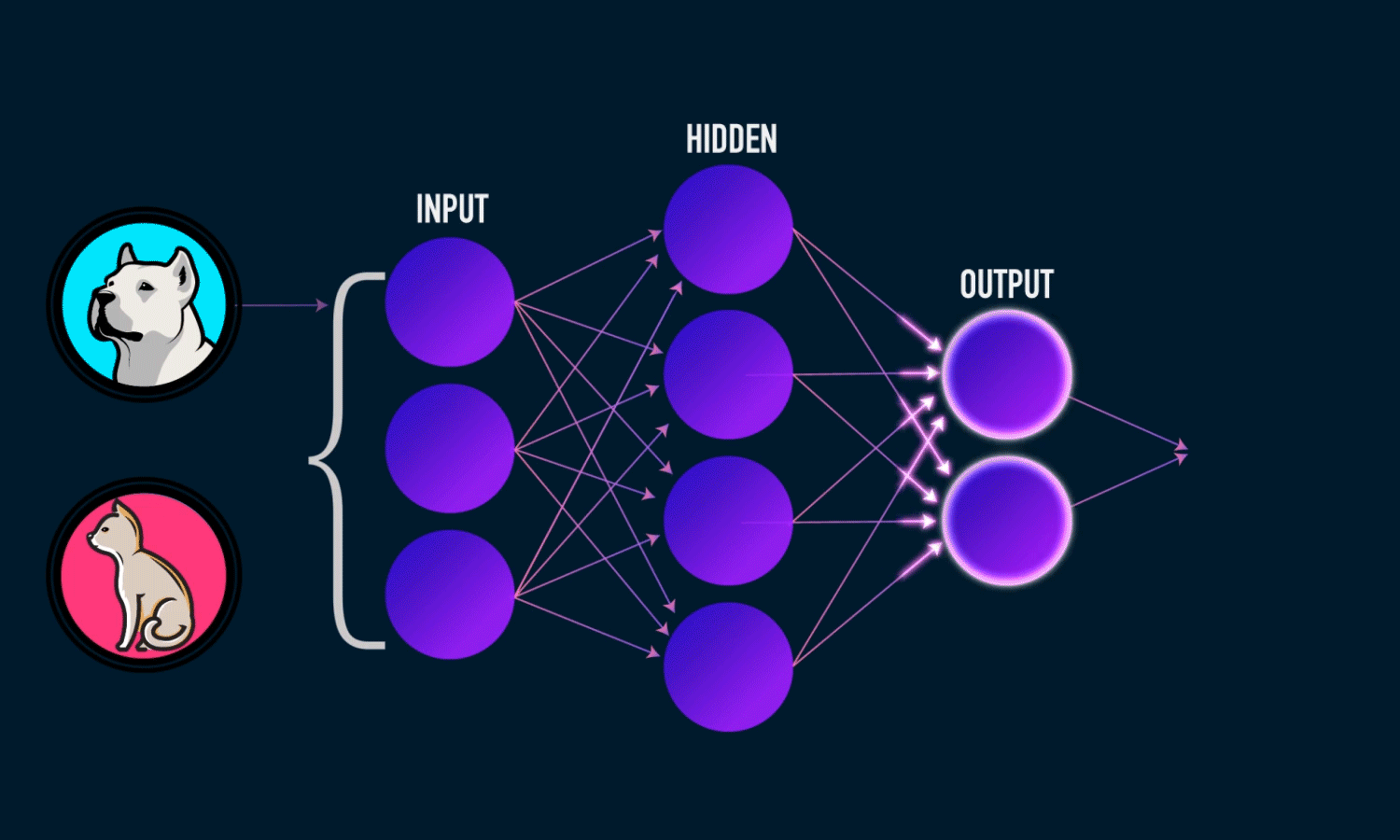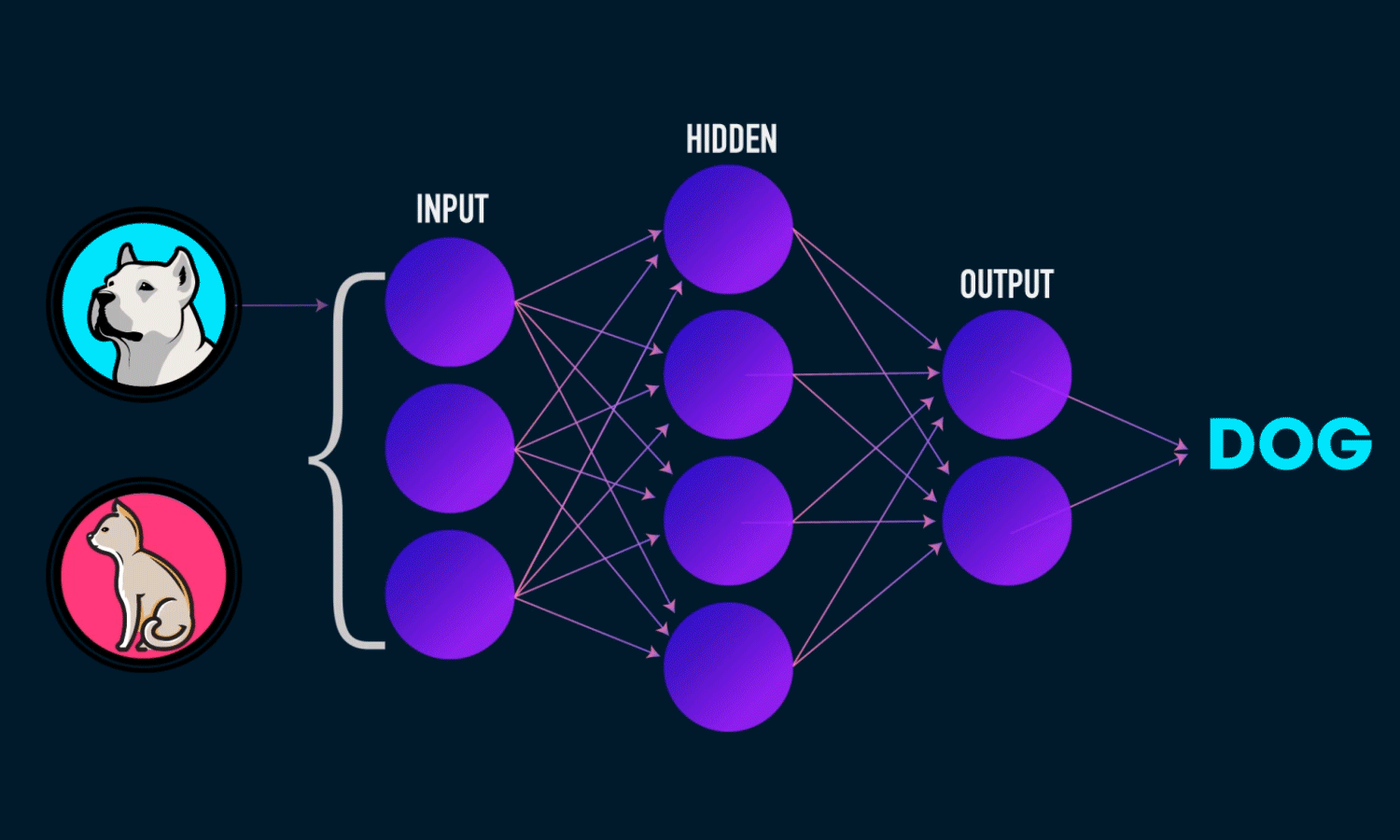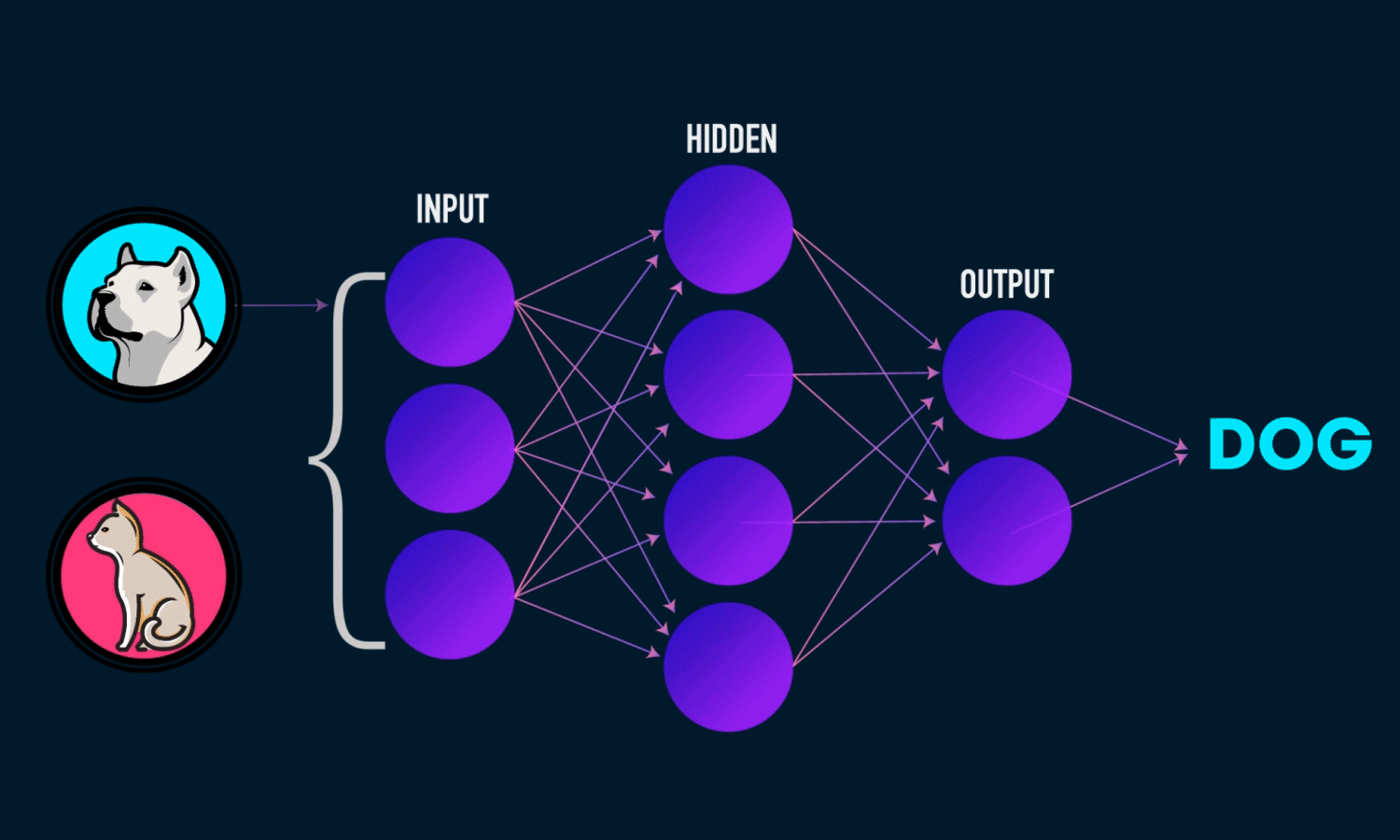
classification is the process of taking an input (picture) and outputting a
class (like ‘dog’). This is done with the help of CNN which comes
under Deep Learning Neural Networks. Image below contains hyperlink
to GIF.
1.
Open up Google Colab from here.
2.
Click File
-> New Notebook.
3.
Click Runtime -> Change runtime type Under notebook
settings, change Hardware Accelerator from None to GPU (increases
speed for computations).
You
have a free notebook, with free GPU and free memory. We will use fastai, which
sits on top of PyTorch, a popular Python library and generally faster than
TensorFlow. fastai’s course-v3 is
one of the best courses you’ll come across for deep learning. It uses a code-first, theory-later approach
and you’ll be able to build models, just like this, and enter competitions
without having to do tons of maths homework.
4.
Let’s make a custom dataset so that we can make sure our
pictures are just right. For this, we’ll have to go through 4 steps –
5.
|
5.
|
Enable the Fatkun Batch Download Extension here (for
Chrome) so that we don’t have to manually save the images.
|
|
|
6.
|
Go to Google Images and type in the first topic ‘minion
bob’. Once around 50 images are loaded, click on the Fatkun extension and
select Download [Current Tab]. You can choose any number of
images but for me, 50 images works just as good, plus it’s easier to handle.
|
|
7.
|
|
You’ll get a tab like the picture above. Unselect the
invalid pictures like the icons or the incorrect ones. Click download.
Repeat this process for all the topics you’ve chosen and at of this you’ll
have all your topics in folders like this.
|
|
8.
|
Create a new folder “Minions Dataset” and store all
these image folders there. Change the name of the folders too. Something easy
like — Bob, Kevin and Stuart.
|
|
|
9.
|
We’re ready to upload this to GitHub so that you can
access them in your Colab notebook. You can also upload this to Drive or
directly to your notebook but that takes up a lot of data. If you want to get
started with Git and GitHub, check this out.
Otherwise, feel free to use my dataset :)
|
We can set
up fastai in our Colab notebook via writing this command in a cell at the top
of our notebook, like this, then run -
#setting up fastai
!curl -s https://course.fast.ai/setup/colab | bash
Press Shift+Enter to
run a cell. Also, keep saving your notebook.
%reload_ext autoreload
%autoreload 2
%matplotlib inline
%
is not Python code, rather called ‘magics’. It does two things — it reloads
automatically if someone’s changing underlying library code while you’re
running this and if you want to plot something, it plots it here using matplotlib.
from fastai.vision import *
from fastai.metrics import accuracy
These
two lines load the fastai library. You can read the docs here or
just remember that fastai.vision imports all the tools necessary for image
classification which comes under Computer Vision. Go to the
repository where you’ve uploaded your dataset. Click on Clone then
copy the link and paste it after ! git clone
! git clone
https://github.com/Priyansi/minionsDataset.git
What
this does is that it downloads your entire dataset so that we can access it
easily from this notebook.
PATH = '/content/minionsDataset'
We need to
set up a constant path that will lead to the multiple classes (image folders
for different topics) and this will be different for all of you. To find out
the path, navigate to Files where your dataset is saved. Right-click on
the file/folder you want to find the path of, then select Copy Path.
After doing this much, our notebook should look
something like this –
Phew! Click the file name on top left
and change it to Minions.ipynb.
np.random.seed(24)
tfms = get_transforms(do_flip=False)
data = ImageDataBunch.from_folder(PATH, valid_pct=0.2,
ds_tfms=tfms, size=299, bs=16).normalize(imagenet_stats)
To build a
model we need two things – classes (labels or what those images are) and images.
Since each of the 3 folders we created contains a separate class (label) of
images, our folder names will be the label names.
In fastai,
grabbing all the images and labeling them is made very easy using ImageDataBunch. All our images are in
folders so we use from_folder to extract it. Now we pass
various parameters to this function like -
a)
np.random.seed() gets
you the same random numbers each time you run the script. You can pass any
value to this.
b)
path — The path where the image folders
are. In this case, its value is stored in PATH.
c)
valid_pct — Let’s talk about validation datasets.
·
The train dataset contains the values
on which the model trains (learns) and the test set is used to
check whether what we learned and predicted was right or not. The test set
contains new data.
·
The validation set comes in between. It
is also a set of values that are held back from the model and is used to tune
the hyperparameters (learning rate, epochs, etc) to give more accurate
results so that we can finally test on our test set. We have a
train set but not a validation set. We let fastai create it.
·
ImageDataBunch creates a DataBunch object
that contains various sets like train, validation and
an optional test. We can just split our training set into train and valid by
passing a ratio to valid_pct. Generally, that ratio is 0.2 which means 20%
of the training set is set aside for validation.
d)
dfms — To transform the images so that our
model trains better. The get_transforms method. do_flip is
set to false because we don’t want our minions upside down. It’s nauseating.
e)
size — So that all the images are of the same
shape and size. This will create a 299 by 299 square image. Why 299? It’s what
I used, and found the results to be pretty good.
f)
bs — Batch size is the number of images processed at
a time. This depends on the memory you have. You can set this to a higher value
if you have sufficient memory.
g)
normalize() — In nearly all ML tasks, you have
to make all of your data about the same ‘size’ — they are specifically about
the same mean and standard deviation so you need to use normalize(). imagenet_stats applies
the normalization technique used by the famous ImageNet dataset.
Moving on, let’s see what data has in store for us.
data.show_batch(rows=3, figsize=(5, 5))
This will show you some of the contents of your DataBunch object. You can clearly see that they have been zoomed, cropped and labeled.
Let the training commence!
learn = cnn_learner(data, models.resnet101, metrics=accuracy)

In fastai,
we use a learner for something that can learn to fit a model. We will be using
a cnn_learner for the reasons stated above. To this, we pass our
data, a model and the metric, which I’ve chosen as accuracy. You can also
choose error_rate.
For the
model, all you need to know that there’s a particular kind of model called ResNet which works extremely well
nearly all the time. You need to choose the size. You can go with ResNet34, RestNet50 or ResNet101
like I have. This is a pretty huge architecture so you might wanna start small
with RestNet34 since it works faster and then you can increment if you are not
getting the desired output.
As soon as
you run the above line, it downloads something. Well, those are the pre-trained
weights, that is, our model has already been trained to do something and it’s
better than starting with nothing. And the thing it has been trained to do is
recognize thousands of categories in ImageNet.
We
are implementing transfer learning.
We will take a pre-trained model, and then we fit it so that instead of
predicting a thousand categories of ImageNet with ImageNet data, it predicts
the 3 categories of minions using our minions' data.
learn.fit_one_cycle(4)
The best
way to fit models is to use something called one cycle. It’s accurate and
faster. The parameter 4 decides how
many times we show the dataset to the model so that it can learn from it. Each
time it sees a picture, it’s going to get a little bit better. But it’s going
to take time and it means it could overfit. If it sees the same picture too
many times, it will just learn to recognize that picture, not minions in
general.
If the
accuracy of your training set is pretty darn good, it means you’re overfitting.
This can be avoided by using the validation set. We will print out the accuracy
of the model on the validation set alongside so that you’ll recognize when the
model is over-fitting. Now, this is our result –

67%
is not bad. It means we are in the right direction but it’s not good enough. We
can do better folks. Notice that accuracy is constant for the last 3 cycles? The learning
rate is the thing that figures out what is the fastest you can train this
neural network without making it zip off the rails and crash. It basically says
how quickly you’re updating your parameters.
learn.unfreeze()
Before
we find a suitable learning rate, we’ll unfreeze() the model. A CNN
has several layers for a whole lot of computations. What we did previously was
just add a few extra last layers and trained only those. Now we want to train
the whole model, therefore, we’ll use unfreeze().
learn.lr_find()
learn.recorder.plot()
To find a
suitable learning rate, we run lr_find(). And then we plot the losses
against a range of learning rates like this -

Choosing
an appropriate learning rate is mostly intuition but this graph will help you
narrow it down. We are looking for the steepest slope where the model is
learning right before the losses skyrocket, which is between the red lines.
slice will take a start value
and a stop value and train the very first layers at a learning rate of 3e-5,
and the very last layers at a rate of 3e-4, and distribute all the
other layers across that. So we can choose a range rather than just one value.
learn.fit_one_cycle(4, max_lr=slice(3e-5, 3e-4))

learn.save('stage-1')
Next,
we interpret the results. Let’s see where our model betrayed us by using class
interpretation and then plotting the confusion matrix.
interpret =
ClassificationInterpretation.from_learner(learn)
interpret.plot_confusion_matrix()

Our model’s right predictions are along the diagonal and the wrong ones are scattered throughout. But this dull. Let’s look at something more visually appealing.
interpret.plot_top_losses(3, figsize=(5, 5))
Take the first picture. Our model classified that as Kevin when it was actually Bob. All this can be resolved by cleaning up the dataset a bit. But for now, you’re good to go.

Let’s start by uploading an image in the File section. To test our model, we load some images. One place that this can be done is /content/data. As can be seen from the image below, we have loaded 6 images (2 each of Bob, Kevin & Stuart).

img1 = open_image('/content/data/Bob1.png')
image.show()
Now
open the image to make sure it’s the right one. Then, we predict -
learn.predict(img1)
You
should see something like this:

img1 = open_image('/content/data/Stuart1.png')
image.show()
We
predict -
learn.predict(img1)

You can
find the full code here. If you’re still hung up on something, ping me on Twitter. If you
stick around for the next part, I’m gonna show you how to deploy this trained
model without any coding knowledge.





{kind=link}